

L’Edge IA est une innovation technologique qui permet de traiter les données au plus près de la source qui les génère, mais qu’est-ce que cette technologie implique ?
Les algorithmes d’IA sont traités localement, soit directement sur l’appareil ou sur le serveur proche de l’appareil. Les algorithmes utilisent les données générées par les appareils eux-mêmes. Les appareils peuvent prendre des décisions indépendantes en quelques millisecondes sans avoir à se connecter à Internet ni au cloud. L’Edge AI n’a presque pas de limites en ce qui concerne les cas d’utilisation potentiels. Les solutions et applications Edge AI varient des montres intelligentes aux lignes de production et de la logistique aux bâtiments et villes intelligents.
Comment fonctionne l'Edge AI, quels types d'avantages pour les entreprises apporte-t-il et comment démarrer avec ?
👉 Edge Computing
L’Edge Computing consiste en plusieurs techniques qui permettent la collecte, l’analyse et le traitement des données à la périphérie du réseau. Cela signifie que la puissance de calcul et le stockage de données se situent là où se produit la collecte de données réelle. Que signifie la périphérie du réseau ? Cela dépend du cas d’utilisation – il pourrait s’agir d’un téléphone portable, d’un appareil IoT, d’une voiture autonome ou même d’une tour de cellule.
👉 Intelligence artificielle
En termes généraux, en Intelligence Artificielle, une machine imite la raisonnement humain : tels que la compréhension des langues et la résolution de problèmes. L’intelligence artificielle peut être considérée comme une analyse avancée (souvent basée sur l’apprentissage automatique) combinée à l’automatisation. Cette définition pragmatique couvre toutes les applications actuelles de l’IA.
Vous pouvez considérer l’Edge AI comme une analyse qui se déroule localement et utilise des méthodes d’analyse avancées (telles que l’apprentissage automatique et l’intelligence artificielle), des techniques de Edge Computing (telles que la vision artificielle, l’analyse vidéo et la fusion de capteurs) et nécessite du matériel et de l’électronique adéquats (qui permettent leEdge Computing). De plus, les méthodes d’intelligence de localisation sont souvent nécessaires pour faire fonctionner l’Edge AI.
Les appareils Edge AI comprennent des enceintes intelligentes, des téléphones intelligents, des ordinateurs portables, des robots, des voitures autonomes, des drones et des caméras de surveillance qui utilisent l’analyse vidéo.
Bien que la plupart des analyses et décisions prises par les machines aient déjà lieu en bord, les plus grands avantages sont obtenus lorsque les résultats produits par les appareils sont liés aux processus d’entreprise. Par conséquent, des plateformes de données modernes, capables de gérer de grandes quantités de données de localisation et de diffusion en continu, sont également nécessaires pour permettre un traitement en temps réel.
Lorsque l'Edge Computing est combiné à l'intelligence artificielle, nous obtenons une combinaison imbattable.

L’Edge IA accélère la prise de décision, rend le traitement de données plus sécurisé, améliore l’expérience utilisateur avec une hyper-personnalisation et réduit les coûts en accélérant les processus et en rendant les dispositifs plus économes en énergie.
Un exemple de ceci pourrait être un outil portatif utilisé dans une usine. L’outil est intégré avec un microprocesseur qui utilise un logiciel d’Edge IA. La batterie de l’outil dure plus longtemps lorsque les données n’ont pas besoin d’être envoyées vers le cloud. L’outil collecte, traite et analyse les données en temps réel, et après la journée de travail, l’outil envoie les données vers le cloud pour une analyse ultérieure. Un outil intégré à l’IA pourrait par exemple s’éteindre en cas d’urgence. Le fabricant reçoit des informations précieuses sur la façon dont ses produits fonctionnent et peut utiliser ces informations pour un développement ultérieur de produits.
Latence
Le transfert de données vers le cloud et retour prend du temps. Ce temps, la latence, est généralement d’environ 100 millisecondes. Souvent, ce n’est pas un problème, mais parfois, les exigences en matière de temps de réponse sont si élevées que même la latence est trop grande. Par exemple, les nouvelles Porsche sont équipées de centaines de capteurs qui produisent en continu une quantité massive de données sur le fonctionnement de la voiture. Les Porsche sont intégrées avec des puces NVIDIA et le logiciel d’analyse Kinetica. L’automatisation prend le volant si nécessaire.
Si la vitesse de la voiture est de 200 km/h, une latence de même quelques millisecondes est trop grande. La décision de freiner arrive trop tard lorsque la voiture est déjà dans le fossé.
L'analyse en temps réel
Avec le Edge Computing, il est possible d’obtenir une analyse presque en temps réel. L’analyse a lieu en une fraction de seconde, ce qui est crucial dans les situations critiques. Prenons les machines sur une ligne de montage en usine. Si un robot sur la ligne de montage est activé à un moment ou trop tard, cela peut entraîner un produit endommagé ou le produit peut continuer à avancer sur la ligne de montage sans être traité. Si l’erreur passe inaperçue, le produit défectueux peut finir sur le marché ou causer des dommages à des stades ultérieurs de la production.
Scalabilité
L’organisation de recherche IDC a prédit qu’il y aura 41,6 milliards de dispositifs IoT connectés générant 79,4 zettaoctets de données en 2025. À mesure que les volumes augmentent, de nouvelles méthodes innovantes pour l’analyse efficace et le traitement des données sont nécessaires.
Lorsque la plupart du traitement des données est effectué localement, à la périphérie, le service centralisé ou le transfert de données ne deviendra pas un goulot d’étranglement. Les cas d’utilisation de l’Edge IA impliquent généralement de grandes quantités de données. Si vous devez traiter les données d’image vidéo provenant de centaines ou de milliers de sources différentes simultanément, transférer les données à un service cloud n’est pas une solution viable.
Sécurité de l'information et vie privée
Moins de données dans le cloud signifient moins d’occasions d’attaques en ligne. Le Edge opère souvent dans un réseau fermé, ce qui rend le vol d’informations plus difficile. De plus, il est plus difficile de faire tomber un réseau composé de plusieurs dispositifs.
En général, on peut dire que tout ce qui a un élément de sécurité doit être effectué à la périphérie. En exemple, nous pouvons penser aux systèmes de surveillance de sécurité intelligente dans une usine. Lorsque les machines ne fonctionnent pas comme elles le devraient ou lorsque les gens se déplacent dans une zone interdite, l’alarme doit se déclencher avant même qu’un accident ne se produise.
Comme déjà mentionné, lorsque le traitement des données se produit localement, il n’est pas nécessaire d’envoyer les données à un environnement cloud. En raison de cela, il devient assez difficile d’accéder aux données sans autorisation. De plus, les données sensibles qui sont traitées en temps réel, telles que les données vidéo, peuvent n’exister que pour un très court instant avant de disparaître. Dans ce type de situations, il est plus facile de garantir la confidentialité et la sécurité des données, car l’intrus doit avoir accès direct au dispositif physique où les données sont traitées.
Prise de décision automatisée
Il y a des centaines et des centaines de capteurs dans une voiture autonome qui mesurent constamment, par exemple, la position du véhicule et la vitesse de rotation des pneus. L’ordinateur de conduite peut prendre les décisions nécessaires concernant le direction, le freinage et l’utilisation de l’accélérateur en fonction des données collectées par les capteurs – automatiquement.
Réduction des coûts
En raison de la scalabilité de l’analytique et de la réduction de la latence dans la prise de décisions critiques, la périphérie peut apporter des réductions importantes de coûts pour votre organisation. En plus du temps, la périphérie peut économiser de la bande passante – la nécessité de transfert de données est réduite. Cela rend également les dispositifs plus économes en énergie.
Le traitement et l’analyse de grandes quantités de données dans le cloud n’est pas bon marché. Si vous voulez des temps de réponse très rapides lors de l’analyse de flux de données constants ou de grandes quantités de données historiques, vous devrez acheter beaucoup de capacité auprès d’un service cloud, tel que le calcul GPU. Parfois, cela se révèle si cher que cela ruine les calculs de cas d’affaires.
Il va sans dire que l’Edge IA nécessite une puissance de calcul locale et nécessite un investissement en matériel, mais même ainsi, l’Edge IA est souvent la solution la plus rentable en termes de coûts.
Comment l'Edge IA fonctionne ?

Quels sont les fondements et les principes de base de l’Edge IA ? Comment cela fonctionne-t-il en réalité ? Les mots clés ici sont l’apprentissage automatique, l’IA et l’Edge Computing.
Dans un environnement d’apprentissage automatique typique, nous commençons par entraîner un modèle pour une tâche spécifique sur un jeu de données approprié. L’entraînement du modèle signifie en fait que celui-ci est programmé pour trouver des motifs dans le jeu de données d’entraînement et évalué sur un jeu de données de test pour valider ses performances sur d’autres jeux de données non vus, qui devraient avoir des propriétés similaires à celles sur lesquelles le modèle est formé.
Une fois le modèle formé, il est déployé ou, en d’autres termes, « mis en production ».
Il peut maintenant être utilisé pour l’inférence dans un contexte spécifique, par exemple en tant que microservice. L’inférence désigne le processus d’utilisation d’un algorithme d’apprentissage automatique formé pour faire des prévisions.
Une fois que le modèle fonctionne comme prévu, les prévisions produites par le modèle peuvent être utilisées pour améliorer les processus d’entreprise. Typiquement, le modèle fonctionne via une API. La sortie du modèle est ensuite soit communiquée à un autre composant logiciel, soit dans certains cas, visualisée sur l’interface utilisateur de l’application pour l’utilisateur final.
Le cloud ne suffit pas
L’essor des ressources informatiques et de stockage de données bon marché grâce à l’infrastructure cloud offre de nouvelles opportunités pour tirer parti de l’apprentissage automatique à grande échelle. Cependant, cela a un coût en termes de latence et de défis de transfert de données en raison de limitations de bande passante.
Former un modèle d’apprentissage automatique est une tâche coûteuse en calcul, bien adaptée à un environnement basé sur le cloud, tandis que l’inférence nécessite des ressources informatiques relativement faibles.
Compte tenu des nouvelles tendances de l’Industrie 4.0, des systèmes autonomes et des dispositifs IoT intelligents, l’ancien paradigme d’exécution de l’inférence dans le cloud commence à devenir de plus en plus inapproprié à mesure que les besoins en prédictions en temps réel augmentent.
Si un modèle d’apprentissage automatique se trouve dans le cloud, nous devons d’abord transférer les données requises (entrées) de l’appareil final, que le modèle utilisera ensuite pour prédire les sorties. Cela nécessite une connexion fiable et si nous supposons que la quantité de données est importante, le transfert peut être lent ou, dans certains cas, impossible. Si le transfert de données échoue, le modèle est inutile.
Dans le cas d’un transfert de données réussi, nous devons toujours faire face à la latence. Le modèle a naturellement un temps d’inférence, mais les prévisions doivent également être communiquées à l’appareil final. Il n’est pas difficile d’imaginer que, dans les applications critiques, où une faible latence est essentielle, ce type d’approche échoue.
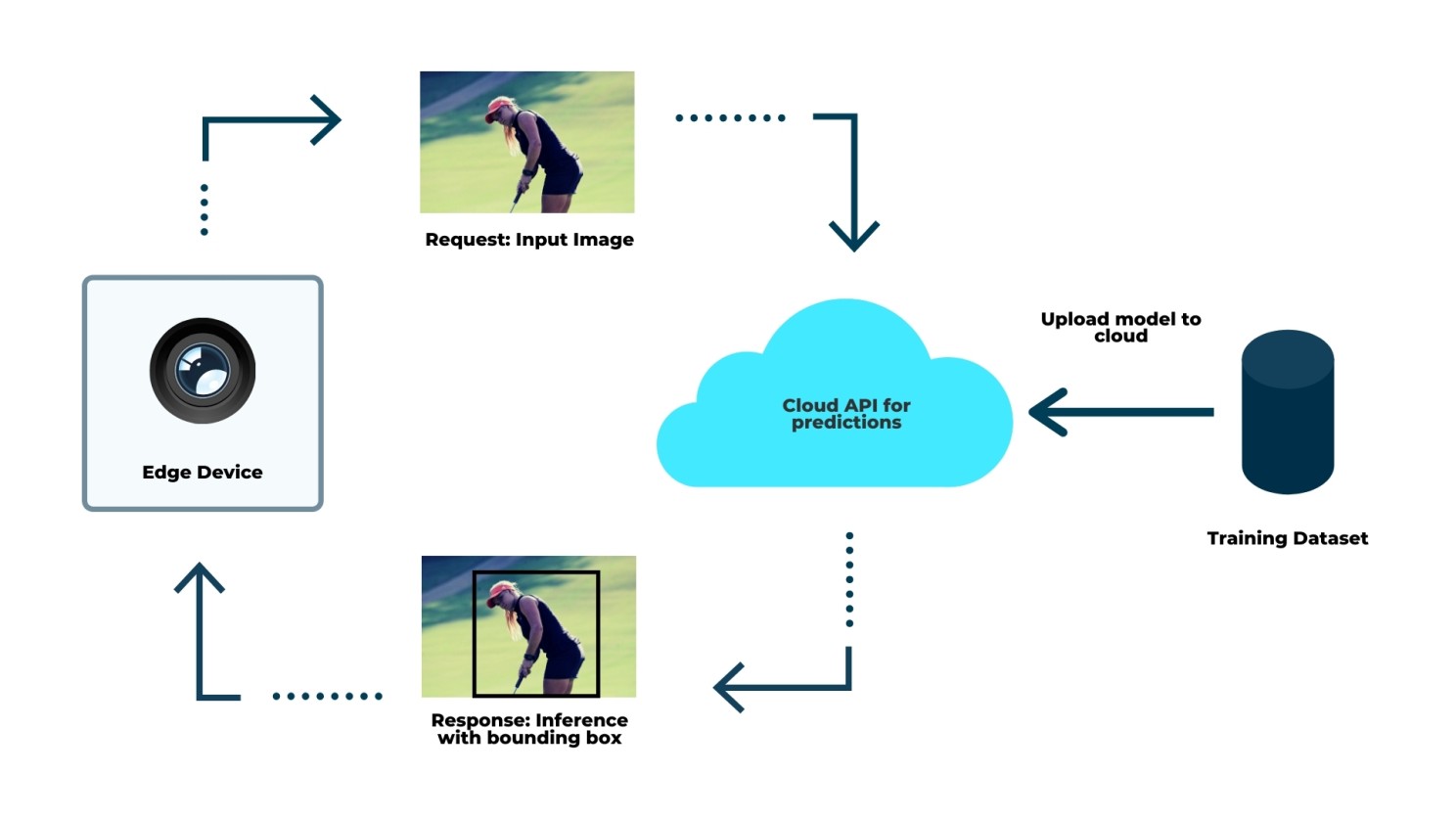
Avec l'Edge AI, le modèle fonctionne sur l'appareil de bord sans nécessiter de connexion au monde extérieur en tout temps.
Le processus de formation d’un modèle sur un jeu de données consolidé et son déploiement en production est toujours similaire au cloud computing, cependant. Cette approche peut poser plusieurs problèmes.
Premièrement, il nécessite la création d’un jeu de données en transférant les données des appareils vers une base de données cloud, ce qui est problématique en raison des limitations de bande passante. Deuxièmement, les données d’un appareil ne peuvent pas être utilisées de manière fiable pour prédire les résultats d’autres appareils.
Enfin, la collecte et le stockage d’un jeu de données centralisé est difficile sous l’angle de la vie privée. Les restrictions législatives telles que le RGPD créent des barrières importantes à l’entraînement de modèles d’apprentissage automatique. De plus, la base de données centralisée est une cible lucrative pour les attaquants. Par conséquent, l’affirmation populaire selon laquelle le traitement en bordure répond seul aux préoccupations en matière de vie privée est fausse.
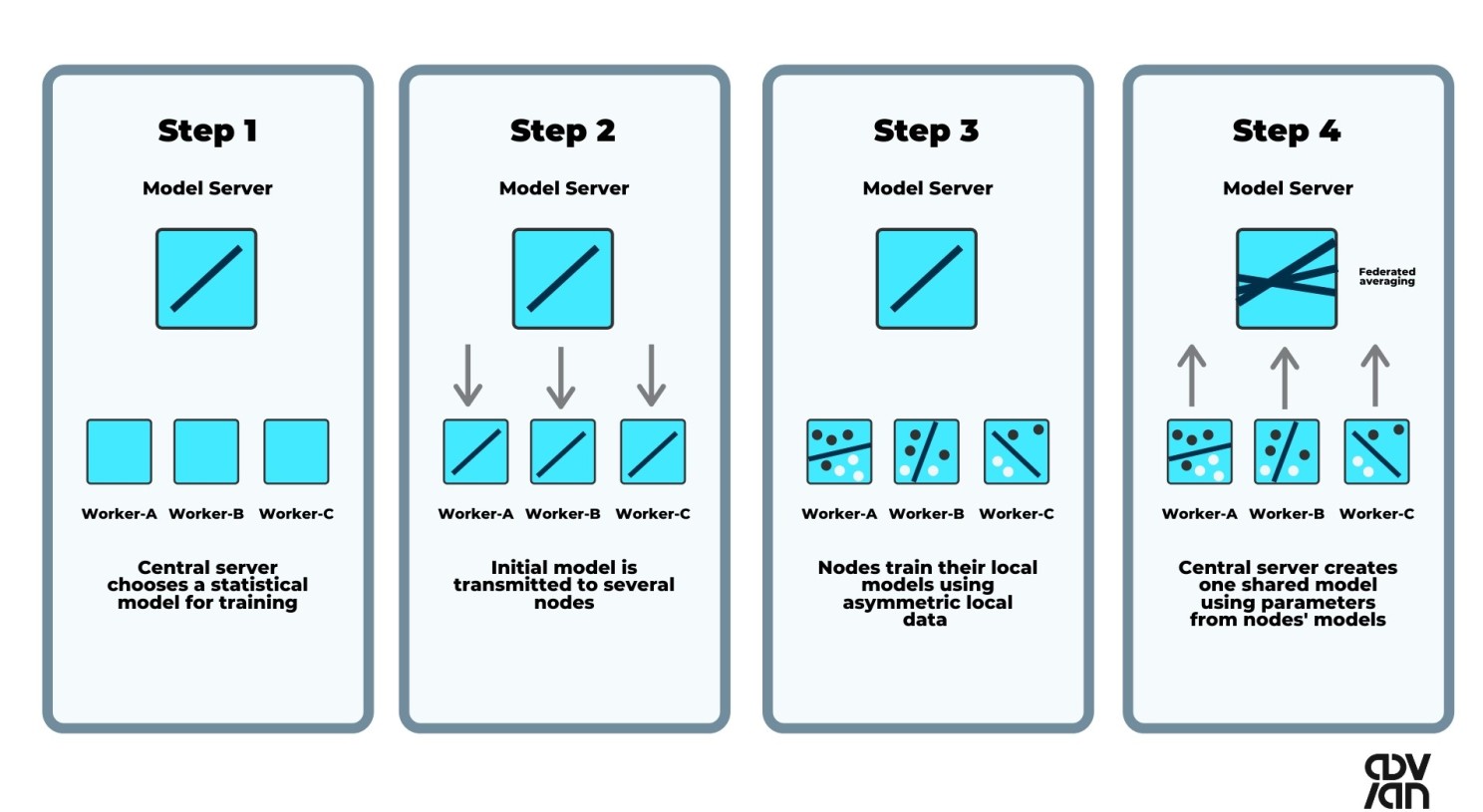
Pour résoudre les problèmes mentionnés ci-dessus, l’apprentissage par fédération est une solution viable.
L’apprentissage par fédération est une méthode pour former un modèle d’apprentissage automatique sur plusieurs dispositifs clients sans avoir accès aux données elles-mêmes.
Les modèles sont formés localement sur les dispositifs et seuls les mises à jour de modèles sont envoyées au serveur central, qui agrège les mises à jour et envoie le modèle mis à jour aux dispositifs clients. Cela permet une hyper-personnalisation tout en préservant la vie privée.
L’Edge Computing ne va pas remplacer complètement le Cloud Computing, mais va plutôt travailler en conjonction avec celui-ci. Il y a toujours de nombreuses applications où l’apprentissage automatique basé sur le cloud est plus performant, et avec l’Edge IA de base, les modèles doivent toujours être formés dans des environnements basés sur le cloud. En général, si les applications peuvent tolérer les latences basées sur le cloud ou si l’inférence peut être exécutée directement dans le cloud, le Cloud Computing est une meilleure option.
Les tendances en matière d'Edge IA et l'avenir

Il y a toujours beaucoup de battage publicitaire associé à de nouvelles technologies, mais il existe plusieurs raisons concrètes à la croissance du marché de l’Edge IA.
Selon le rapport sur la croissance du marché mondial des logiciels d’Edge IA, le marché des logiciels d’Edge IA seul passera de 346,5 millions de dollars à environ 1,1 milliard de dollars d’ici 2024. Le marché de l’hardware et de la consultance en Edge IA croîtra à la même vitesse. Grand View Research estime que le marché mondial de l’Edge Computing croîtra de 37,4 pour cent par an et sera valorisé à 43,4 milliards de dollars d’ici 2027.
Le réseau 5G permet la collecte de gros flux de données rapides.
La construction des réseaux 5G débute progressivement et initialement ils seront mis en place très localement et dans les zones densément peuplées. La valeur de la technologie Edge IA augmente lorsque l’utilisation et l’analyse de ces flux de données sont effectuées aussi près que possible des dispositifs connectés au réseau 5G.
Les quantités massives de données générées par l'IoT
La technologie IoT et les capteurs produisent de telles quantités de données qu’il est souvent difficile, voire impossible en pratique, de les collecter. Par exemple, les derniers avions Airbus A350 ont 50 000 capteurs qui collectent 2,5 téraoctets de données par jour. Cela représente plus de données que tout le data warehouse de Teradata de Wal-Mart en 1992.
Les données ne signifient rien si elles sont déconnectées de leur lieu d’origine et n’ont pas de métadonnées décrivant la signification des données. Par conséquent, il n’y a rien de suffisant à récupérer les données. En résumé, on pourrait dire que seul l’Edge IA rend possible une utilisation complète des données IoT très médiatisées. Une quantité massive de données de capteurs peut être analysée localement et les décisions opérationnelles peuvent être automatisées. Seules les données les plus essentielles sont stockées dans un entrepôt de données situé dans le cloud ou dans un centre de données.
L'expérience client
Les gens attendent une expérience fluide et sans faille des services. De nos jours, un simple délai de quelques secondes peut facilement gâcher l’expérience client. Le calcul en périphérie répond à ce besoin en éliminant le délai causé par le transfert de données.
De plus, les capteurs, les caméras, les processeurs GPU et autres matériels deviennent constamment plus abordables, de sorte que des solutions de IA en périphérie personnalisées et très produits sont de plus en plus accessibles à un nombre croissant de personnes.
Si vous avez lu jusqu’ici, vous vous demandez probablement déjà comment les solutions d’Edge IA pourraient fonctionner dans le cadre de votre startup.
Le succès en matière d’Edge profitera à ceux qui auront du courage et un esprit ouvert pour saisir les opportunités : être agile, oser échouer, apprendre de ses erreurs et élargir votre succès vers de nouveaux modèles d’affaires et développement de services innovants.


